
模型共224篇 第7页
排序

港大北航等1bit大模型引热议,IEEE刊物评“解决AI能源需求”!
极限量化,把每个参数占用空间压缩到1.1bit!IEEE Spectrum专栏,一种名为BiLLM的训练后量化(PTQ)方法火了。通俗来讲,随着LLM参数规模越来越大,模型计算的内存和资源也面临着更大的挑战。...

英伟达最强通用大模型Nemotron-4登场
许久未更新大模型的英伟达推出了150亿参数的Nemotron-4,目标是打造一个能在单个A100/H100可跑的通用大模型。最近,英伟达团队推出了全新的模型Nemotron-4,150亿参数,在8T token上完成了训练...

微调Mistral-7B实现86.81%准确率
小模型也能解锁数学能力,无需多模型集成,7B模型在GSM 8 k数据集上性能超越70B!对于小型语言模型(SLM)来说,数学应用题求解是一项很复杂的任务。比如之前有研究结果显示,在GSM 8K基准测...
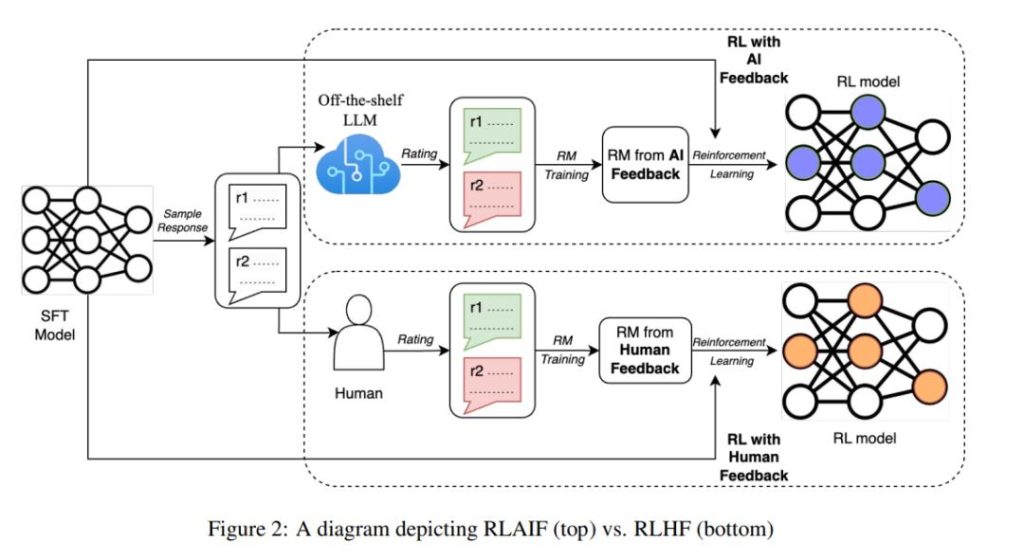
谷歌提出基于AI反馈的强化学习
与基于人类反馈的强化学习(RLHF)相媲美的技术,出现了。近日,Google Research 的研究人员提出了基于 AI 反馈的强化学习(RLAIF),该技术可以产生人类水平的性能,为解决基于人类反馈的强化...

亚马逊刚投40亿美元,谷歌等又要投20亿,Anthropic 估值狂飙
为挑战OpenAI,Anthropic 遵循了与对手类似的道路。据科技新闻网站 The Information 报道,在宣布亚马逊高达 40 亿美元的新投资后不久,人工智能初创公司 Anthropic 正在就 20 亿美元融资进行早...

智能的本质就是压缩?马毅团队5年心血提出「白盒」Transformer
来自UC伯克利,港大等机构的研究人员,开创性地提出了一种「白盒」Transformer结构——CRATE。他们通过将数据从高维度分布压缩到低维结构分布,实现有效的表征,从而进一步实现了有竞争力的模型...

LLM生成延迟降低50%!DeepSpeed团队发布FastGen
DeepSpeed-FastGen结合MII和DeepSpeed-Inference实现LLM高吞吐量文本生成。GPT-4和LLaMA这样的大型语言模型(LLMs)已在各个层次上成为了集成AI 的主流服务应用。从常规聊天模型到文档摘要,从...

Runway官宣下场通用世界模型!解决视频AI最大难题
Runway突然发布公告,宣称要开发通用世界模型,解决AI视频最大难题,未来要用AI模拟世界。最近AI视频赛道的Pika 1.0大火,两位华人创始人团队半年做出的产品几乎碾压了Runway接近两年的发展成果...

让 Kimi Chat 学完了整本周易,给 Sam Altman 算了一卦
最近,Kimi Chat 的上下文长度从 20 万汉字升级到了200 万汉字,10 倍的差距已经足够产生一次质变,做很多之前做不了的事情。感谢月之暗面给了提前测试的机会,我们直接开测!场景1:做SEO搜...

比GPT-4还强,20亿参数模型做算术题,准确率几乎100%
语言模型做数学题,能力又升级了。当前,大型语言模型 (LLM) 在处理 NLP 领域的各种下游任务方面已经表现出卓越的能力。特别是,GPT-4、ChatGPT 等开创性模型已经接受了大量文本数据的训练,使...


搜索





