稳定AI以其稳定扩散文本到图像生成模型而闻名,但这并不是这家生成AI初创公司感兴趣开发的全部内容。稳定AI现在也进入了代码生成领域。
今天,稳定AI宣布了StableCode的首次公开发布,这是其新的开放式大型语言模型(LLM),旨在帮助用户生成编程语言代码。StableCode提供了三个不同的级别:通用用途的基本模型,指令模型和可以支持多达16,000个标记的长上下文窗口模型。
StableCode模型从开源BigCode项目中获得了一组初步的编程语言数据,然后由稳定AI进行了额外的筛选和微调。最初,StableCode将支持Python、Go、Java、JavaScript、C、Markdown和C++编程语言的开发。
“我们想要用这种模型做的事情与我们为Stable Diffusion所做的类似,后者帮助世界上每个人都成为了艺术家,”稳定AI的研究负责人克里斯蒂安·拉福特在接受VentureBeat独家采访时表示:“我们希望用StableCode模型做同样的事情:基本上允许任何有好点子和问题的人能够编写一个可以解决问题的程序。”
基于BigCode和伟大的想法构建的StableCode训练任何LLM都依赖于数据,对于StableCode来说,数据来自于BigCode项目。使用BigCode作为LLM生成AI代码工具的基础并不是一个新的想法。HuggingFace和ServiceNow在五月份推出了开放的StarCoder LLM,这个模型基本上是基于BigCode构建的。
Stability AI的首席研究科学家Nathan Cooper在接受VentureBeat的独家采访中解释说,StableCode的训练涉及对BigCode数据进行大量的筛选和清理。
“我们非常喜欢BigCode,他们在数据治理、模型治理和模型训练方面做了出色的工作,”Cooper表示:“我们采用了他们的数据集,并对其进行了额外的筛选,以提高质量,并构建了模型的大上下文窗口版本,然后在我们的集群上进行了训练。”
Cooper表示,Stability AI还在核心BigCode模型之外执行了许多训练步骤。这些步骤包括在特定编程语言上的连续训练。
“它遵循了在自然语言领域中所做的非常类似的方法,您首先对通用模型进行预训练,然后在特殊的任务集(在这种情况下是语言)上进行微调,”Cooper说。
StableCode更长的标记长度是代码生成的改变者除了其基于BigCode的基础,StableCode的长上下文版本可能会为用户带来显著的好处。
StableCode的长上下文窗口版本具有16,000个标记的上下文窗口,稳定AI声称这比任何其他模型都要大。Cooper解释说,更长的上下文窗口使得可以使用更专业和复杂的代码生成提示。这还意味着用户可以让StableCode查看包含多个文件的中等大小代码库,以帮助理解和生成新的代码。
Cooper说:“您可以使用这个更长的上下文窗口让模型更多地了解您的代码库,以及其他文件中定义的其他函数。因此,在建议代码时,它可以更贴合您的代码库和需求。”
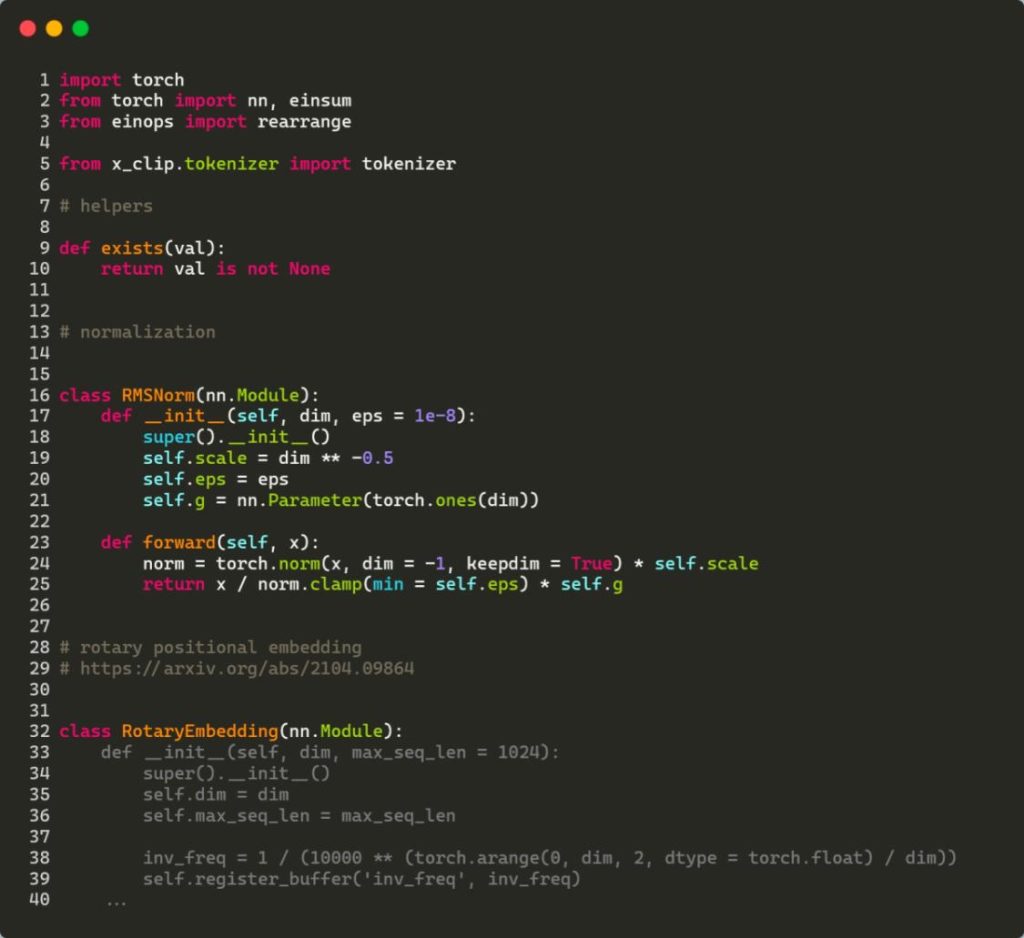
通过旋转位置嵌入(RoPE)实现更好的代码生成StableCode,像所有现代生成性AI模型一样,基于Transformer神经网络。
与StarCoder用于其开放式生成性编程AI模型的位置输出的ALiBi(带线性偏差的Attention)方法不同,StableCode使用了一种称为旋转位置嵌入(RoPE)的方法。
Cooper表示,Transformer模型中的ALiBi方法往往更看重当前标记,而不是过去的标记。在他看来,这对于代码并不是理想的方法,因为与自然语言不同,代码没有固定的叙述结构,没有开始、中间和结尾。代码功能可以在应用流程中的任何时点定义。
“我认为编码本身并不适用于将当前重要性加于过去的思想,所以我们使用RoPE,这种方法不会出现将当前重要性大于过去的偏见。”
StableCode仍处于早期阶段,初次发布的目标是看开发人员如何接受和使用这个模型。
“我们将与社区进行互动和合作,看看他们会提出哪些有趣的方向,并探索生成开发者领域,”Cooper表示。